
Why models without provenance are already doomed
You can celebrate another trillion parameters if you like. It won’t fix the fact that most models today are built on data of unknown origin, unknown integrity, and unknown manipulations, and they still ship because “it works on the benchmark.” Benchmarks don’t litigate. Benchmarks don’t pay damages. Benchmarks don’t tell you whether your dataset was subtly poisoned three supply chains ago. Provenance does.
The invisible substance you’re actually scaling
What are we scaling when we scale models? Not intelligence. We are scaling assumptions about data: that it’s authentic, consented, licensable, unpoisoned, untainted by our own outputs, and stable over time. Each assumption is an unpriced liability. Stack enough of them and you don’t have a model; you have opaque leverage, a towering position balanced on collateral you never audited.
And leverage, as we all know, is intoxicating because nothing looks wrong until everything does.
If you can’t roll back, you never owned it
We treat “unlearning” as a promise, but it’s a theorem: reversibility requires provenance. Without precise, tamper-evident records of how each datum flowed and where its gradient went, “unlearning” does not really exist. You can delete a file; you cannot delete its influence if the influence isn’t measured, attributable, and bounded. Saying “we’ll retrain” is not a strategy; it’s an admission that the system is fundamentally irreparable.
This is the part that should make builders and investors sit up: irreparable systems don’t deserve scale. Scale amplifies defects. If you cannot reverse a contribution, you don’t have a product. You have a slot machine with a glossy UI.
The dead-internet problem for AI
Synthetic content is flooding the commons. Synthetic is not the problem; unlabelled synthetic is. If your pipeline cannot tell at training time whether a sample is human, synthetic, or a derivative of your own prior outputs, you’re optimizing for coherence, not truth. That’s how models get confident about fiction: the data says “sounds right” because the data was the model yesterday. And this isn’t “model collapse.” It's “provenance collapse”: the moment you can no longer tell which fraction of your decision boundary rests on human signals versus your own afterimages.
“But the product works.” Until it doesn’t.
Fixing this is an engineering requirement. Mark synthetic. Bind it to source, generator, parameters, and policy. Weight it differently. People hear “provenance” and think spreadsheets. Stop. Provenance is not an after-the-fact CSV. It’s a first-class constraint that shapes the model’s feasible future. Without it, you can’t:
- Price risk (what are you insuring if you don’t know the inputs?),
- Enforce rights (consent, revocation, derivative use),
- Audit behavior (what training events caused this output?),
- Repair (roll back to a clean state that actually existed).
The unpopular S curve
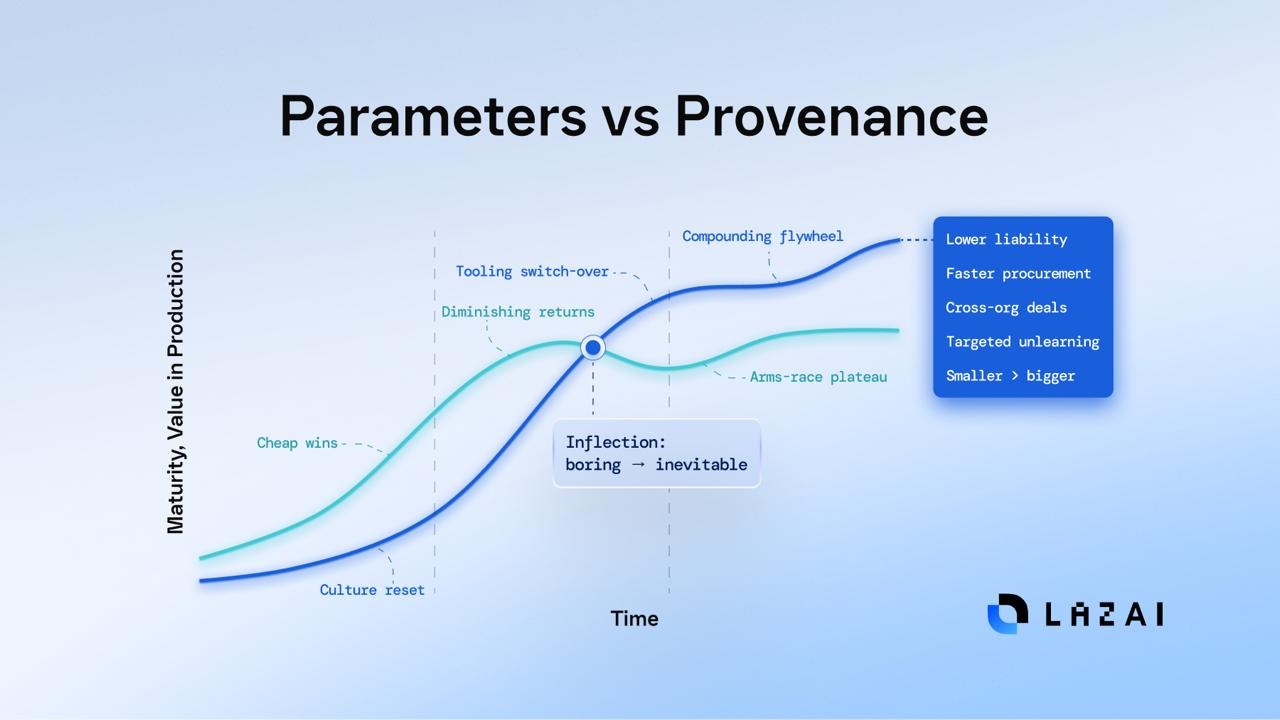
There are two S-curves ahead.
- Curve A (Parameters): cheap wins first, then diminishing returns, then brute-force arms race funded by those who can leave the meter running.
- Curve B (Provenance): slow to start (because you must change culture and tooling), then compounding advantages: lower liability, faster procurement, easier cross-org data deals, targeted unlearning, and the ability to ship smaller models that beat bigger ones because they can operate in regulated, audited, high-value contexts where “black box” is a non-starter.
Most teams are stuck worshiping Curve A because it might give you quick commercial success. The teams that will own the next decade are quietly climbing Curve B. They will look boring in the beginning. Then they will look inevitable. And eventually boring AI wins!
The moment we admit what we’re actually selling
Look at your product honestly. Are you selling answers, or are you selling the ability to trust answers? If it’s the latter, and in any serious domain it is, then provenance is not a feature. It’s the substrate: truth must be machine-readable all the way down.
This is the one idea that changes everything: trust is a first-class compute budget. You plan for it. You meter it. You optimize under it. You never borrow it from strangers and call that innovation. It’s the minimum viable condition for building machines we can govern.
That implies:
- Cryptographic tagging at ingestion: Data doesn’t enter the pipeline without an attached, verifiable identity and policy.
- On-chain or verifiable ledgers: For tamper-resistance and shared truth across organizations that don’t trust each other.
- Attribution accounting: If a class of contributors moves the needle, they see it, they earn from it, and they can revoke or renegotiate.
- Reversible training: If a segment becomes toxic or illegal, you know exactly how to roll back its influence.
The quiet revolution nobody will tweet until it’s too late
The internet didn’t get safer when we added more pages; it got safer when we added protocols. AI will not get safer with more layers; it will get safer with provenance protocols that make falsity expensive and honesty cheap. This is the revolution that won’t trend on Hacker News the day it ships, because it doesn’t produce a viral chart. It produces systems that don’t implode when reality asks hard questions.
If this sounds controversial, good. It should. The controversy isn’t whether provenance matters; the controversy is that we built a trillion-dollar industry while pretending it didn’t.
A note on where we’re experimenting
We’re building around this thesis: data must carry its own provenance and rights wherever it goes. LazAI focuses on verifiable pipelines; DAT (Data Anchoring Token) is our SFT standard to assetize your AI data, specifically binding data, rights, and usage economics; and Lazbubu is a playful, user-facing way to experience agents that remember with consent, prove their sources, and can unlearn on demand. This is an invitation to kick the tires of a future where models come with receipts.
